── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.1 ✔ stringr 1.5.2
✔ lubridate 1.9.4 ✔ tibble 3.3.0
✔ purrr 1.1.0 ✔ tidyr 1.3.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Attaching package: ‘cowplot’
The following object is masked from ‘package:lubridate’:
stamp
Day 2 Learning Objectives
Compare different measures of central tendency and spread
Identify various types of sampling bias
Understand the difference between observation studies and experiments
Investigate the idea of sampling and the relationship between sample size and variability
1. Measures of Central Tendency and Variability
3 ways to describe the distribution of a quantitative variable:
Shape
Center
Spread
We can assess the distribution of data by looking at graphs as well as by numerical calculations (descriptive statistics).
1.1 Shape
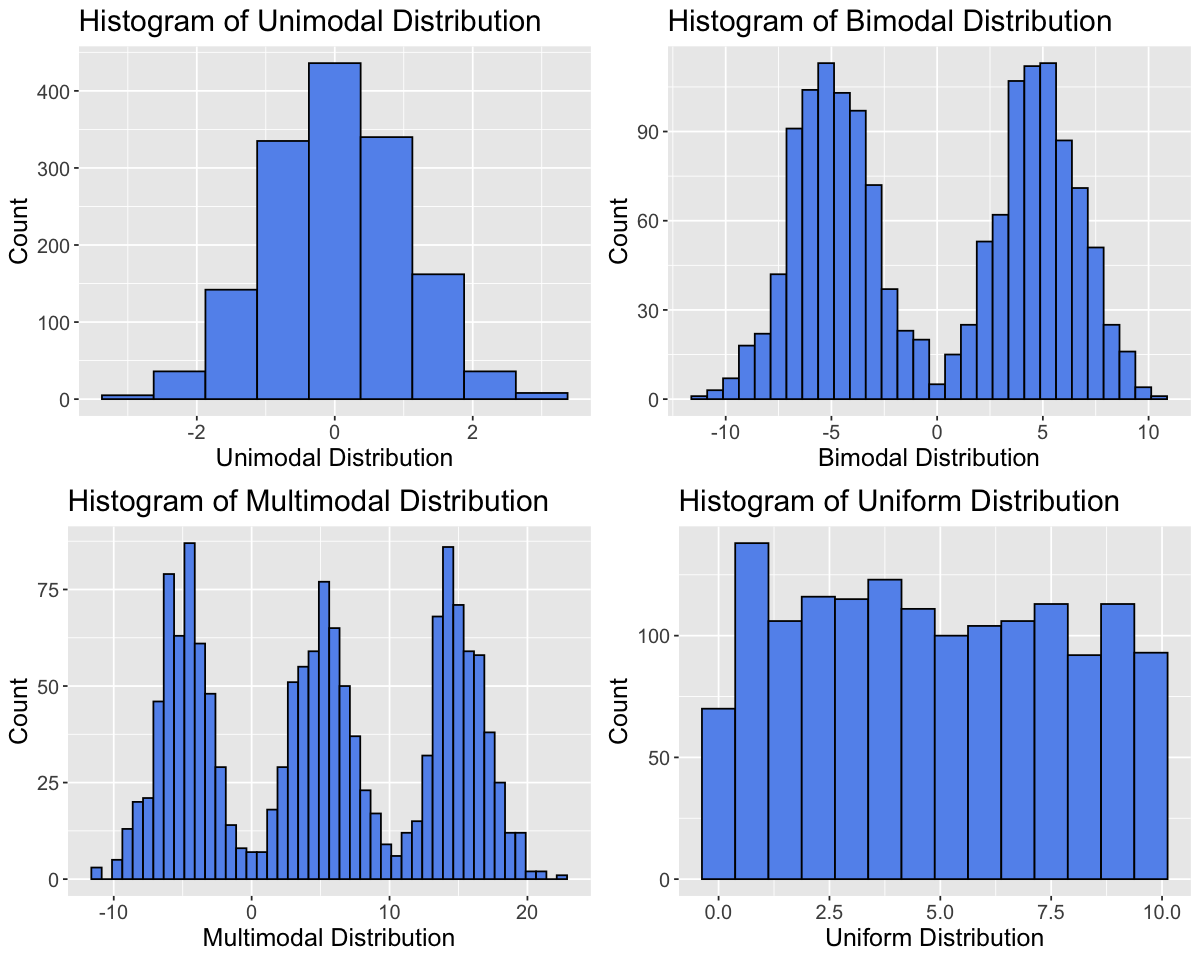
To assess the shape of a distribution, we can consider the modality (number of peaks), symmetry (symmetric vs. skewed) and outliers.
Modality
set.seed(2000) # Setting the seed allows us to get reproducible results# Generate datadata_tibble <-tibble(var1=rnorm(1500,0,1),var2=c(rnorm(750,-5,2), rnorm(750,5,2)),var3=c(rnorm(500,-5,2), rnorm(500,5,2),rnorm(500,15,2)),var4=runif(1500,0,10))variable_names <-c("Unimodal Distribution", "Bimodal Distribution", "Multimodal Distribution", "Uniform Distribution")data_tibble <- data_tibble |>rename(setNames(names(data_tibble), variable_names))
options(repr.plot.width =10, repr.plot.height =8)# Create histograms for each variableplots <-lapply(variable_names, function(var_name) {ggplot(data_tibble, aes(x = .data[[var_name]])) +geom_histogram(binwidth =0.75, fill ="cornflowerblue", color ="black") +labs(title =paste("Histogram of", var_name), x = var_name, y ="Count") +theme(text =element_text(size =15))})# Arrange plots in a gridplot_grid(plotlist = plots, ncol =2)
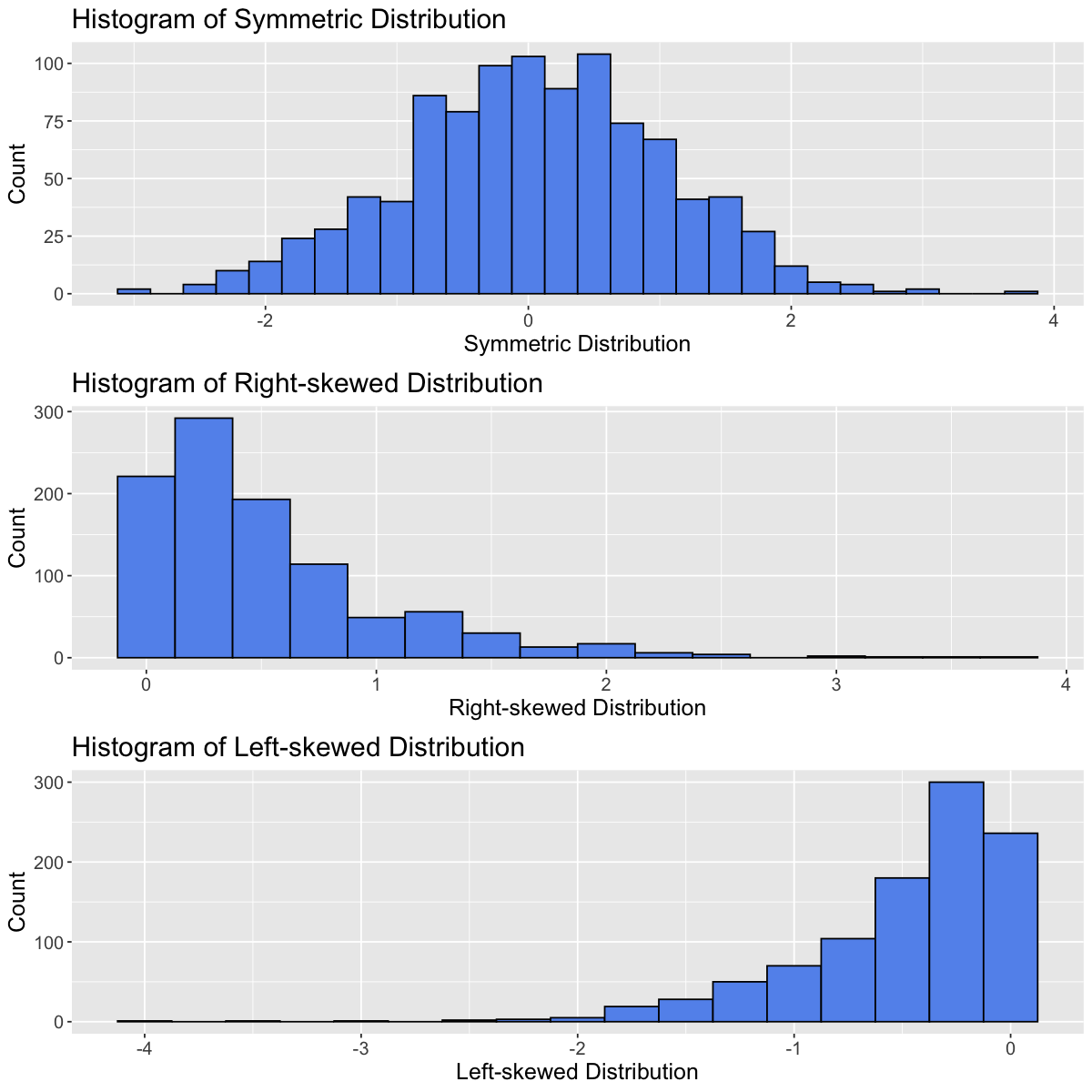
Symmetry
Distributions can be symmetric or skewed (left-skewed or right-skewed).
set.seed(930) # Setting the seed allows us to get reproducible results# Generate datadata_tibble <-tibble(var1=rnorm(1000,0,1),var2=rexp(1000,2),var3=-rexp(1000,2))variable_names <-c("Symmetric Distribution", "Right-skewed Distribution", "Left-skewed Distribution")data_tibble <- data_tibble |>rename(setNames(names(data_tibble), variable_names))
options(repr.plot.width =10, repr.plot.height =10)# Create histograms for each variableplots <-lapply(variable_names, function(var_name) {ggplot(data_tibble, aes(x = .data[[var_name]])) +geom_histogram(binwidth =0.25, fill ="cornflowerblue", color ="black") +labs(title =paste("Histogram of", var_name), x = var_name, y ="Count") +theme(text =element_text(size =15))})# Arrange plots in a gridplot_grid(plotlist = plots, ncol =1)
Outliers
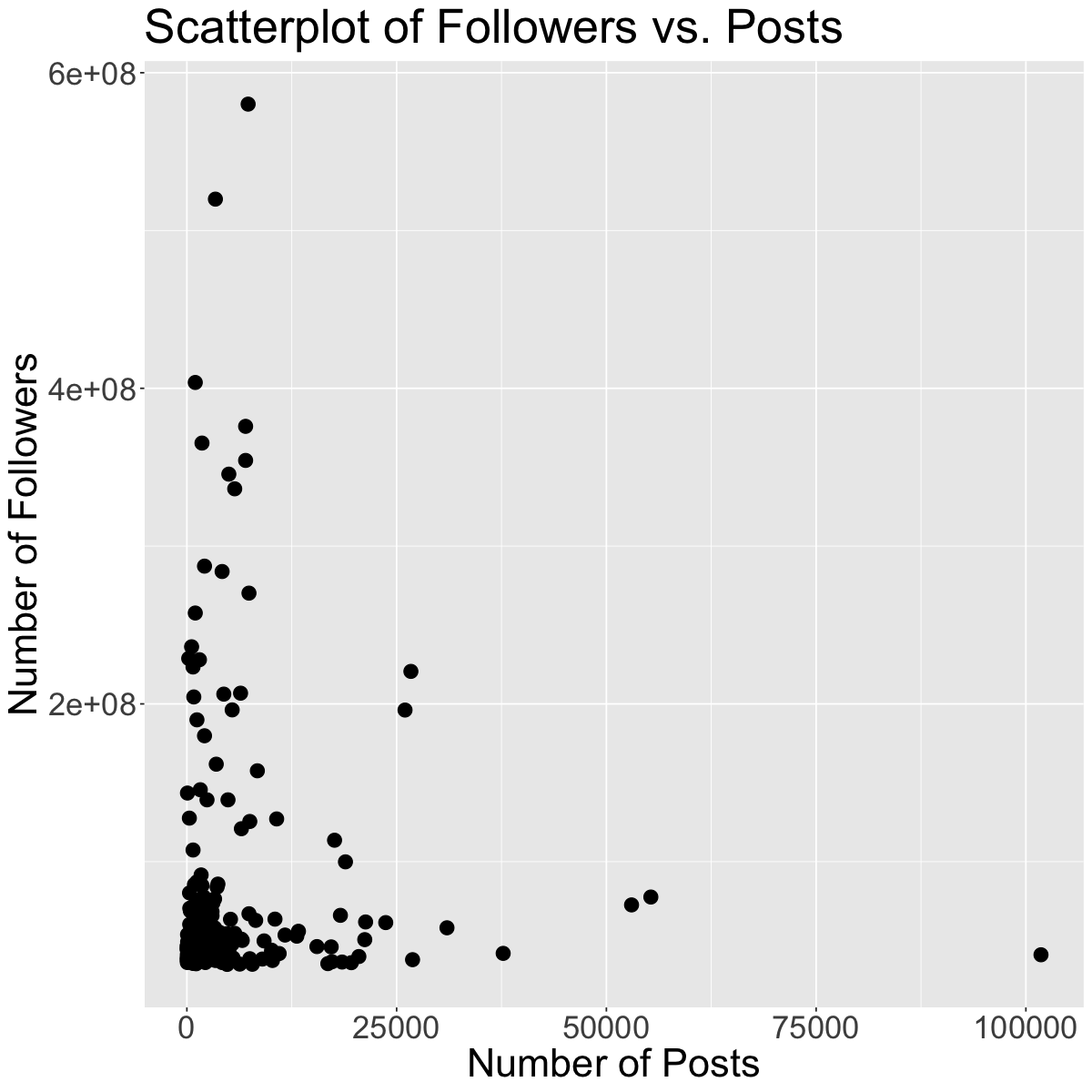
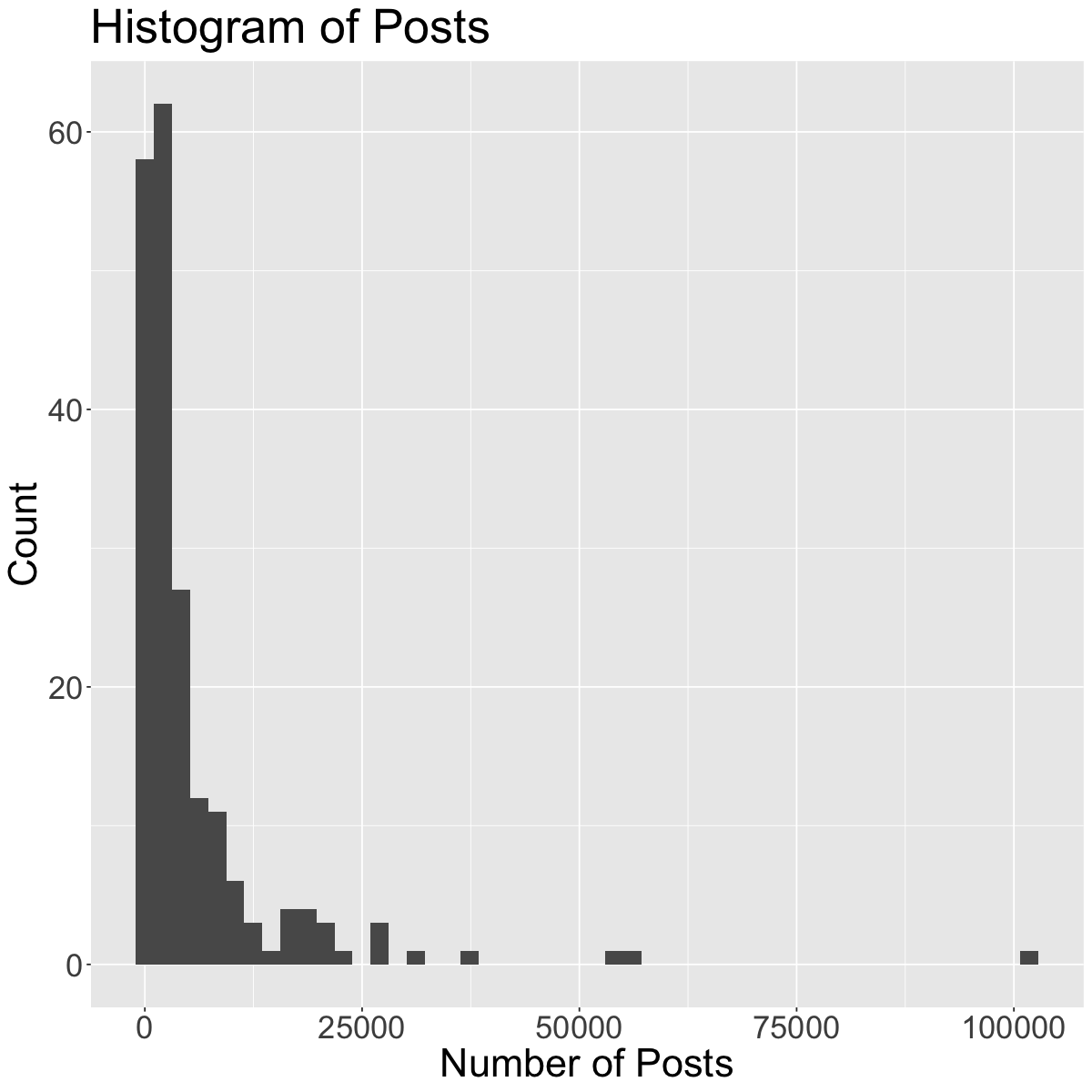
Outliers can seriously influence a variable’s distribution. An outlier is an observation that lies away from the other data points. Recall our scatterplot of Followers vs. Posts for the Instagram data set:
insta <-read_csv('data/insta.csv')head(insta)
Rows: 200 Columns: 8
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (7): name, channel_Info, Category, Posts, Followers, Avg. Likes, Eng Rate
dbl (1): rank
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 200 Columns: 8
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (7): name, channel_Info, Category, Posts, Followers, Avg. Likes, Eng Rate
dbl (1): rank
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
ggplot(insta, aes(x = Posts, y = Followers)) +geom_point(size=4) +theme(text =element_text(size =26)) +labs(x='Number of Posts', y='Number of Followers', color='Channel Info', title='Scatterplot of Followers vs. Posts') # rename axes and add title
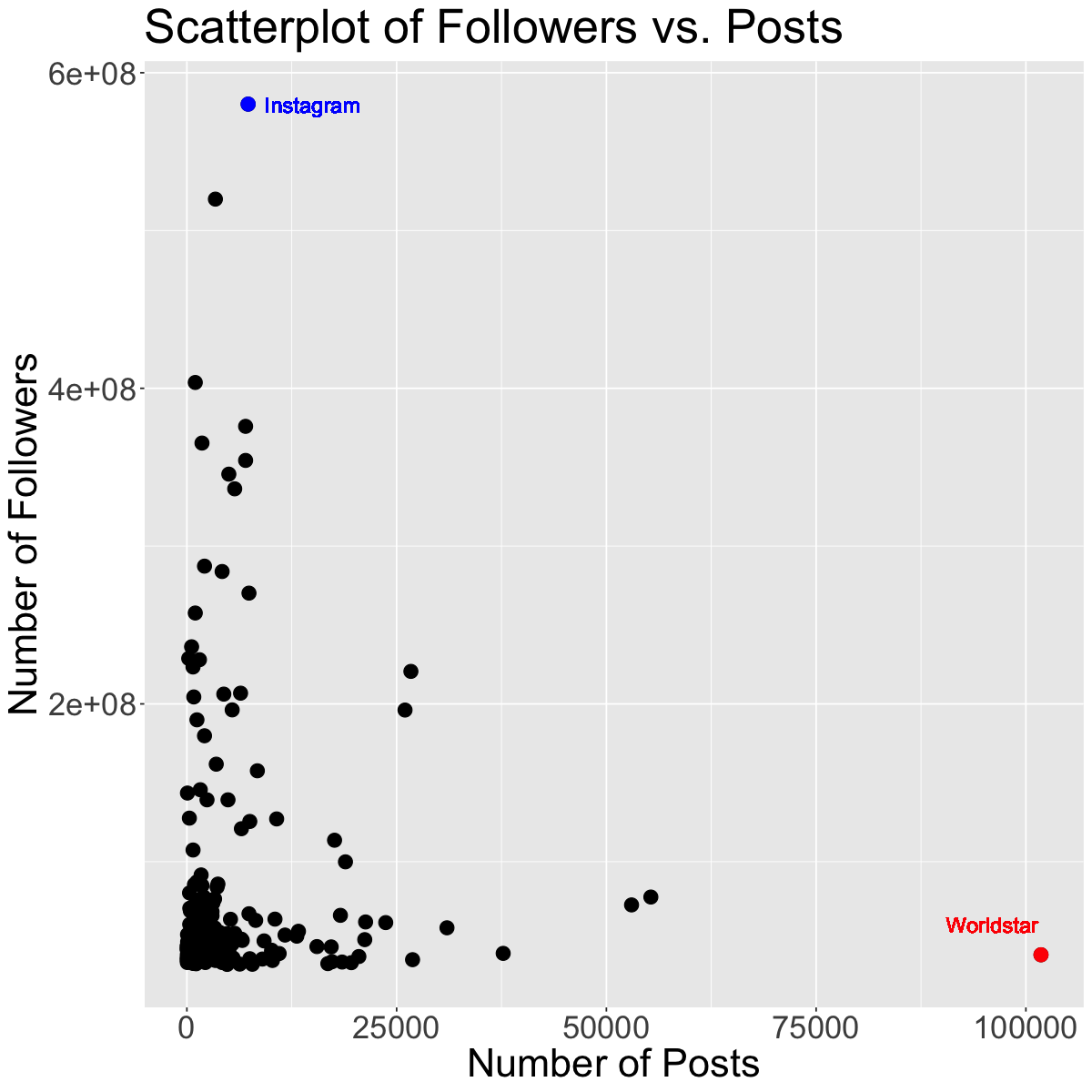
g1 <-subset(insta, name =="worldstar")g2 <-subset(insta, name =="instagram")ggplot(insta, aes(x = Posts, y = Followers)) +geom_point(size=4) +geom_point(data=g1, size=4, color="red") +geom_point(data=g2, size=4, color="blue") +theme(text =element_text(size =26)) +geom_text(x =96000, y =60000000, label ="Worldstar", color ="red", size =5) +geom_text(x =15000, y =580000000, label ="Instagram", color ="blue", size =5) +labs(x='Number of Posts', y='Number of Followers', color='Channel Info', title='Scatterplot of Followers vs. Posts') # rename axes and add title
The red and blue points may be potential outliers. The red point represents the account with the highest number of posts (101800). Although this account has the highest number of posts, they do not have that many followers. Also, the blue point represents the account with the highest number of followers (Instagram), which doesn’t have that many posts, but has the most followers.
Exercise
Going back to the histogram we made of “Posts”, comment on its shape. Be sure to reference the modality, symmetry and outliers (if any).
ggplot(insta, aes(x = Posts)) +geom_histogram(bins=50) +theme(text =element_text(size =26)) +# increase text sizelabs(x='Number of Posts', y='Count', title='Histogram of Posts') # rename axes and add title
1.2 Center
Graphically, the center of a distribution is where most of the observations are concentrated. When looking at the center of a distribution, we can use the mean or median.
The mean is the average of the observations.
The median is the middle observation (i.e., 50% of data above/below it).
Note: If the variable is categorical, you can report the mode (most common/frequent observation)
We can extract these values by using the summarize function:
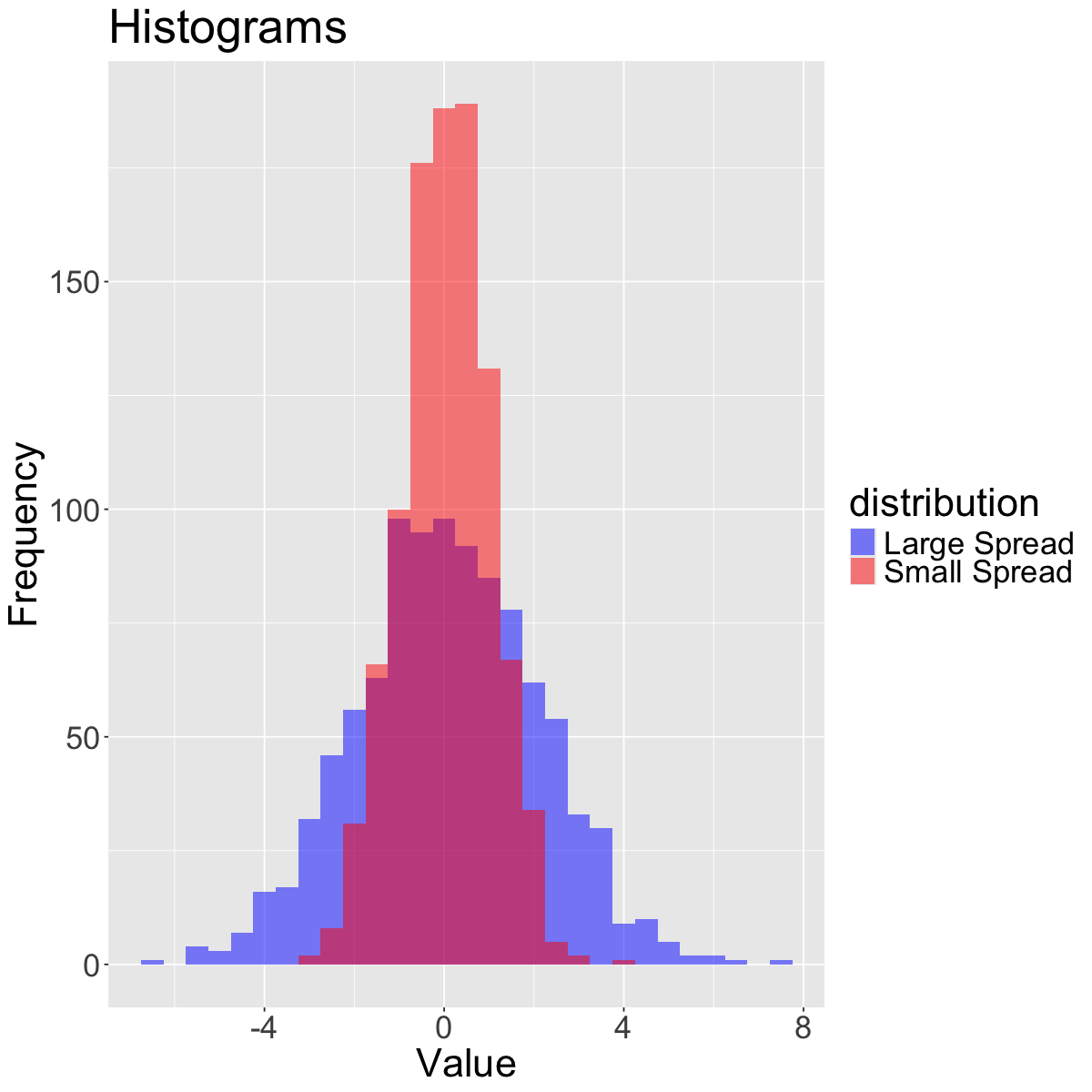
The spread refers to how much variability there is in the data.
set.seed(930)data_small <-rnorm(1000, mean =0, sd =1) # Small spreaddata_large <-rnorm(1000, mean =0, sd =2) # Large spreaddata_tibble <-tibble(value =c(data_small, data_large),distribution =rep(c("Small Spread", "Large Spread"), each =1000))# Create histograms with transparency (alpha)ggplot(data_tibble, aes(x = value, fill = distribution)) +geom_histogram(binwidth =0.5, alpha =0.5, position ="identity") +scale_fill_manual(values =c("blue", "red")) +labs(title ="Histograms",x ="Value", y ="Frequency") +theme(text =element_text(size =26))
When looking at the spread of a distribution, we can use the standard deviation, interquartile range (IQR) or range (difference between maximum and minimum observation).
Quartiles divide a distribution into four equal parts. The Interquartile Range (IQR) is the distance between the first quartile (Q1) and the third quartile (Q3) (i.e., the middle 50% of the data). The second quartile (Q2) is actually the median!
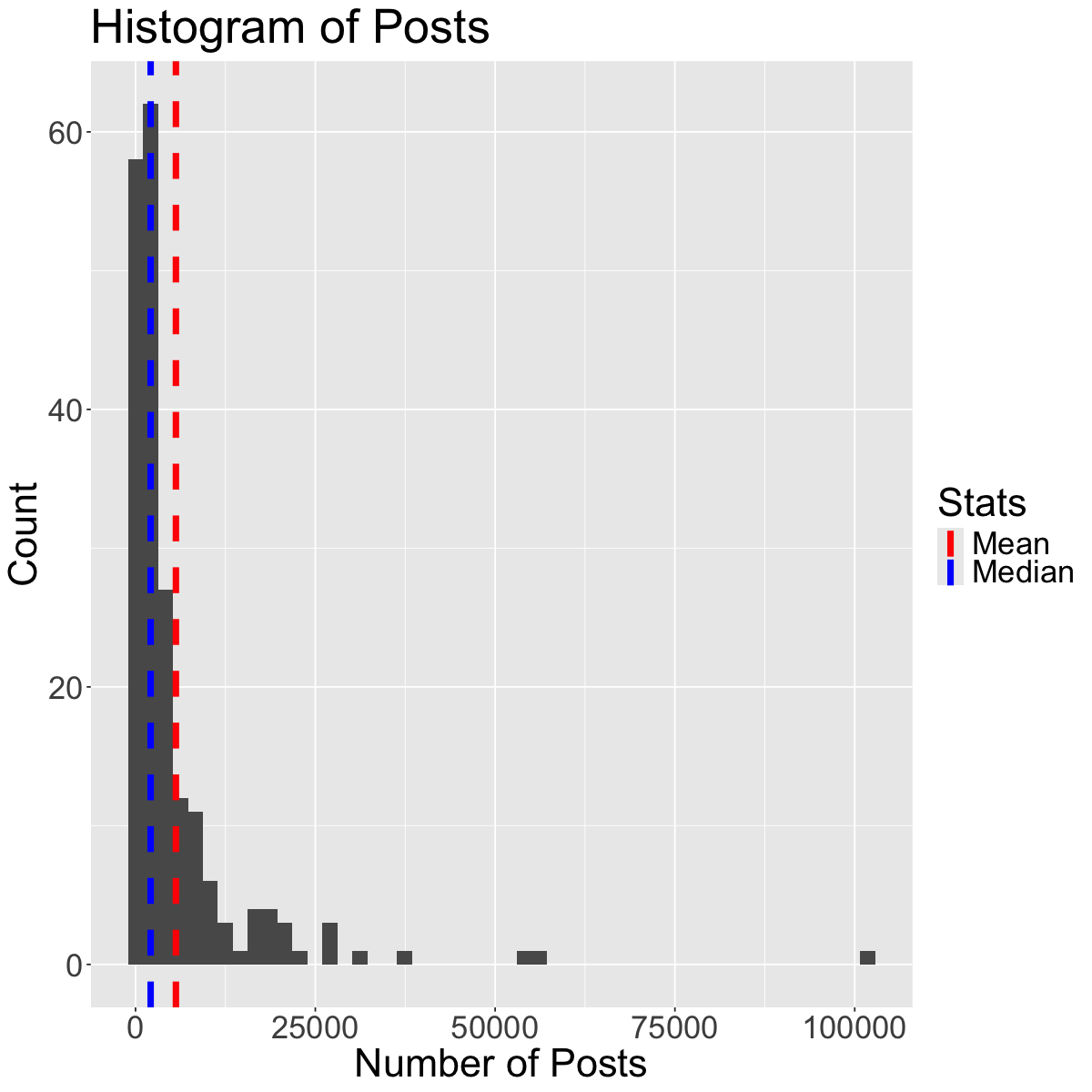
The mean and the standard deviation are typical measures for center and spread. However, they are not resistant to skewness and outliers. A general rule of thumb is:
• If the distribution is roughly symmetric, we use the mean and standard deviation as measures of center and spread. • If the distribution is skewed or has a lot of outliers, we use the median and IQR as measures of center and spread.
Why? For example, if the data is skewed, the mean gets “pulled” out in the direction of the skewness, whereas the mean is less affected. See the plot below to illustrate this concept:
Question: In what scenarios might the range not be a very appropriate choice for a measure of spread? Why?
2. Introduction to Statistical Inference
What is statistical inference?
Statistical inference is the process of using a sample to make conclusions about a wider population the sample came from.
Why?: It’s often expensive or not possible to measure the whole population.
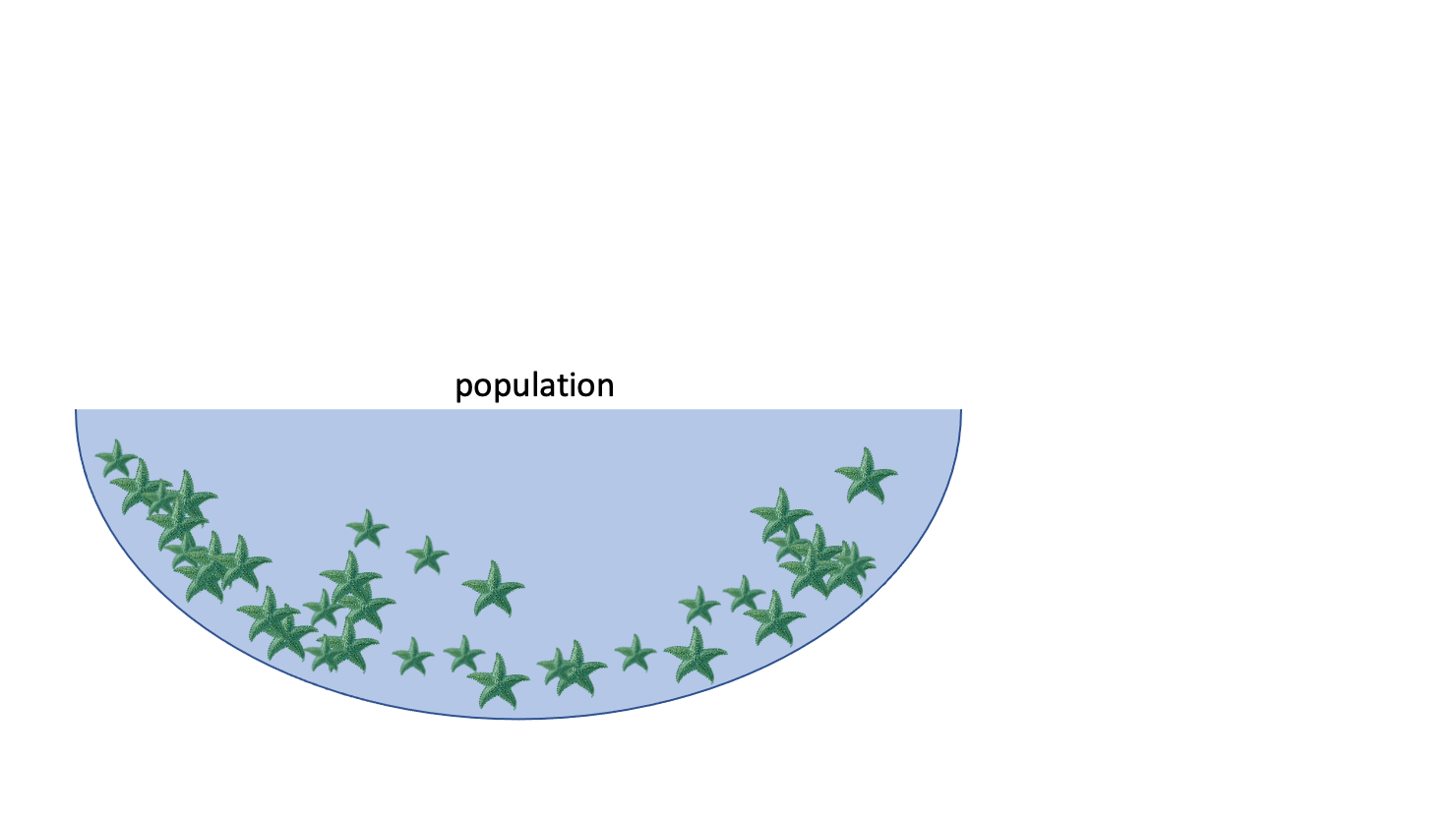
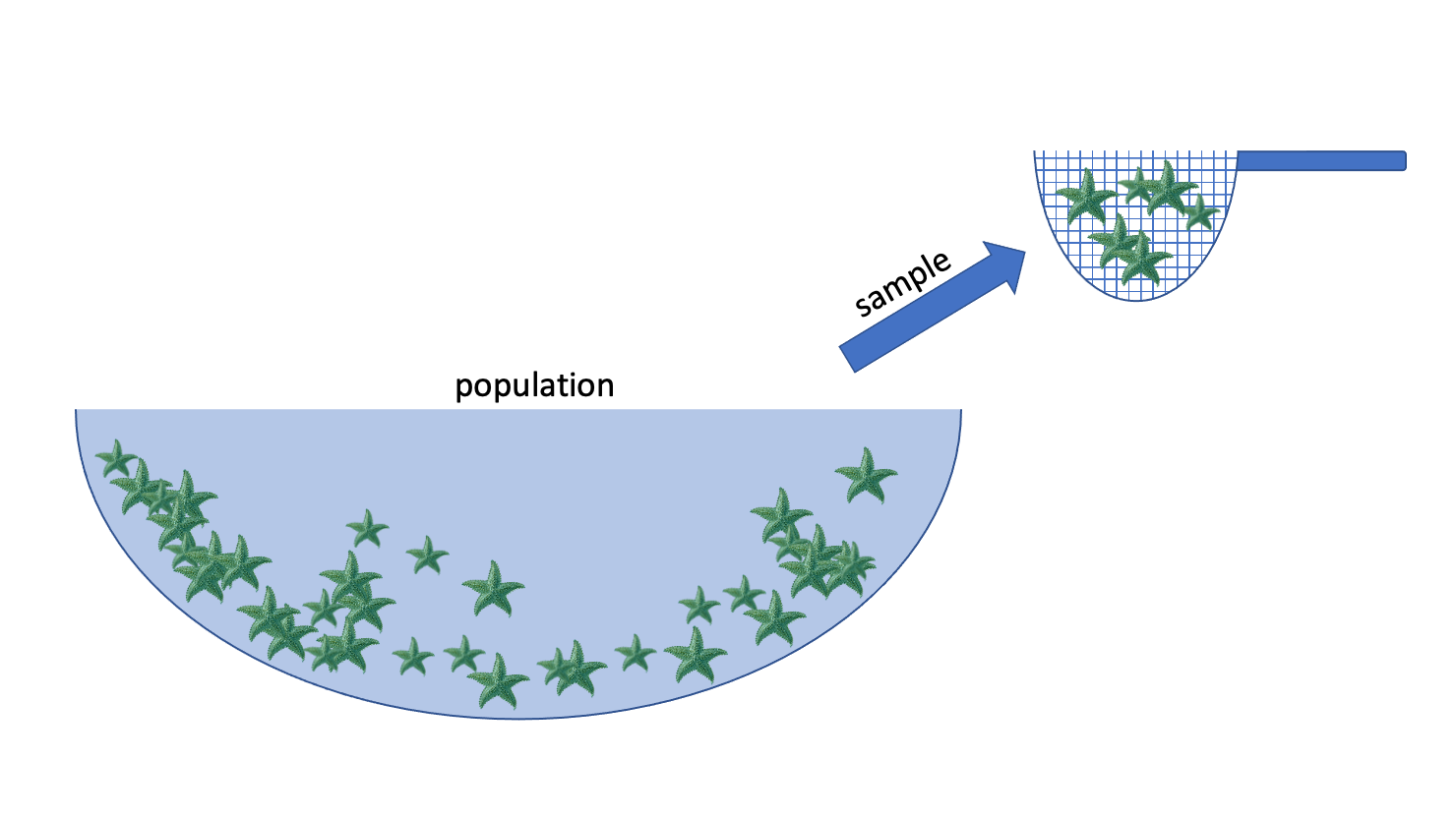
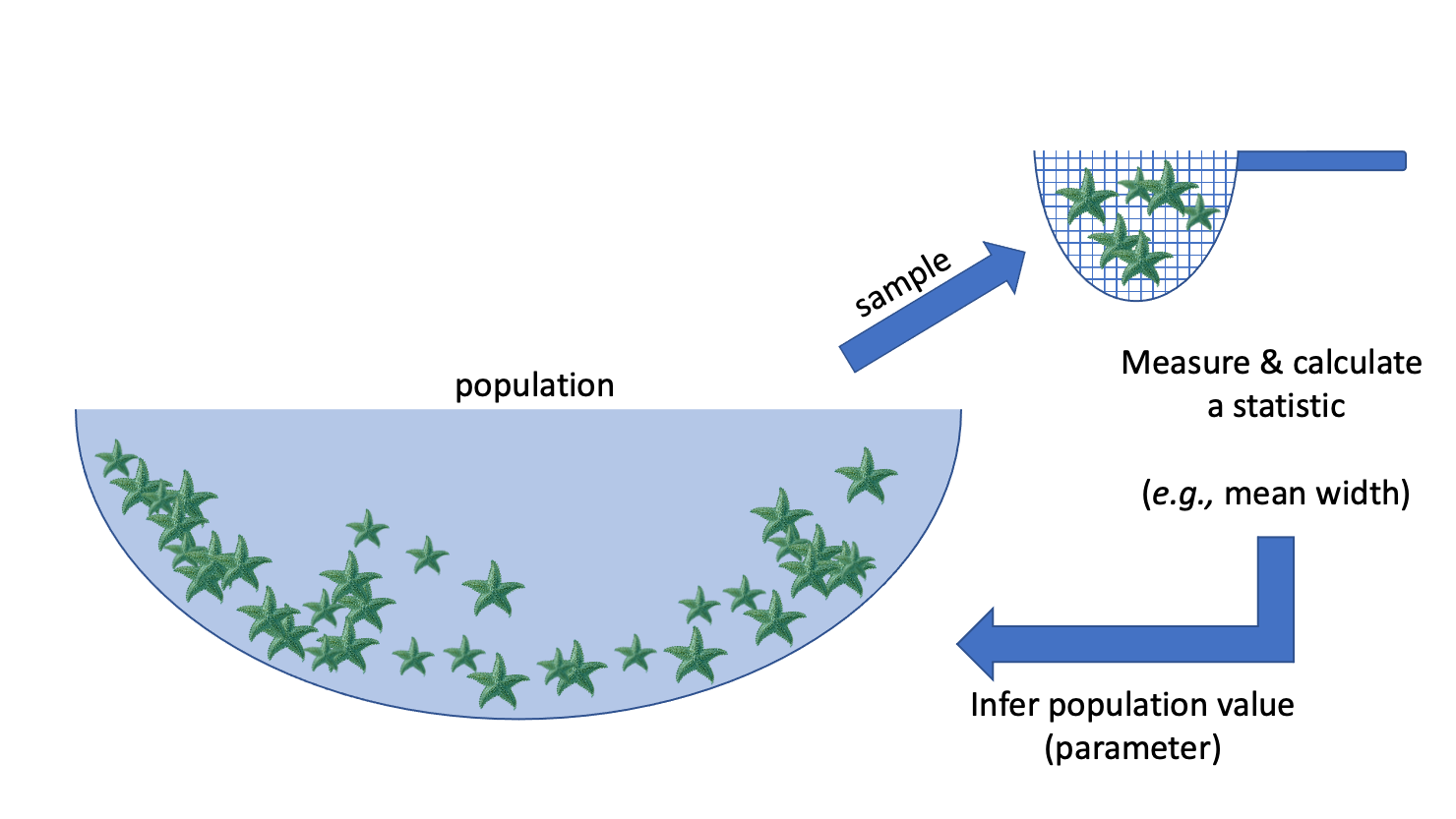
E.g.: we want to know the average width of a species of sea star
Population: collection of all possible observations + their frequency/count
e.g. the widths of the entire population of sea stars
Sample: a randomly selected subset of observations
e.g. I randomly pick 50 sea stars and record their widths
Statistic: something I compute using my sample
e.g. the mean width of the sea stars in my sample
Inference: using the sample to make a conclusion about the whole population, and knowing how uncertain you are about your conclusion
Examples of inference in the wild: market assessment
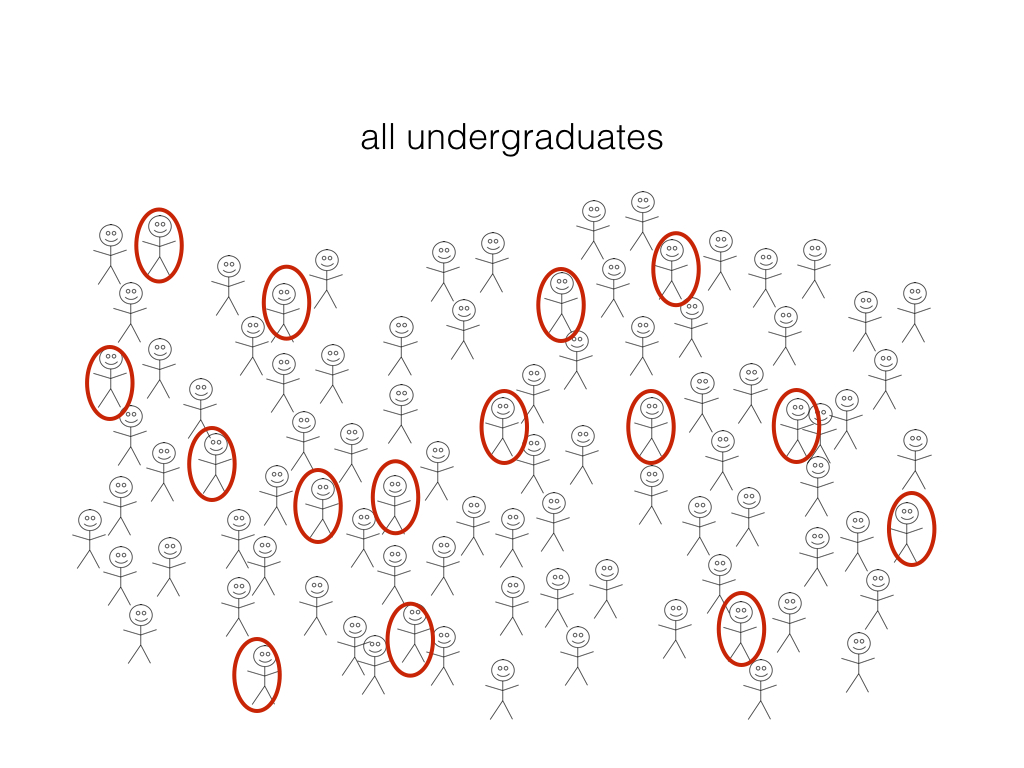
What proportion of undergraduate students have an iphone?
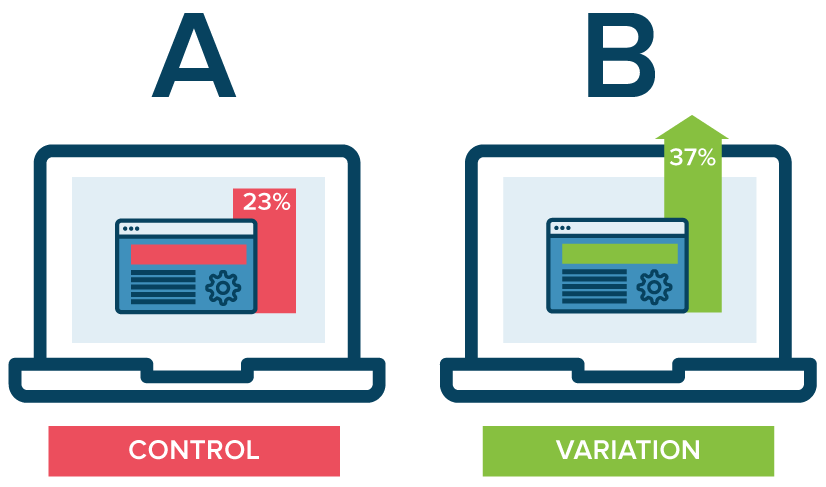
Examples of inference in the wild: A/B testing
Which of the 2 website designs will lead to more customer engagement (measured by click-through-rate, for example)?
2.2 Sampling
When we are collecting a sample, we aim for that sample to be representative of the population of interest.
A sample is biased if certain individuals in the population have a higher chance of being selected.
Exercise
In groups, brainstorm a variety of sampling strategies or scenarios that might result in a biased sample.
Types of Sampling Bias
There are numerous types of sampling bias, including:
Response bias: responder gives inaccurate responses for any reason
Nonresponse bias: person fails to or refuses to respond
Selection bias: certain people may be more or less likely to be selected (e.g., online survey)
Volunteer bias: sampling bias can occur when the sample is volunteers (they may have stronger motivations or opinions)
Recall bias: responder might not accurately recall certain events (e.g., asking someone about something that happened years ago)
Exercise
For the following scenarios, identify a source of potential sampling bias:
A telephone survey calls and asks you if you will support a local politician in the upcoming election.
A survey asks you “when was the last time you visited the dentist?”
At a store, an optional survey is included on the back of the receipt for you to provide feedback on your shopping experience.
At work, your boss provides you with a survey which asks you to answer the question “How effective have I been as a manager?”
While there are many different sampling strategies out there, one way to help ensure that a sample is unbiased and representative of the population of interest is by using random sampling.
Random sampling is an important consideration when designing a statistical study or research project.
2.3 Observational Studies vs. Experiments
Research projects can typically be classified as either observational studies or experiments.
Observational Studies
The researcher observes phenomena without any intervention or controlling any variables.
Variables are recorded or measured as the naturally occur.
No treatments are imposed by the researcher.
Researchers can get an idea about the relationships between variables.
Experiments
The researcher applies a treatment and manipulates variables.
Often times, subjects are randomly assigned to treatment and control groups.
With randomization, researchers can make more definitive causal statements (e.g., variable A caused an increase in variable B).
Exercise
Identify the following scenarios as either an observational study or an experiment:
Students are randomly assigned into two groups, where in group A they have homework assignments and in group B they do not. Their performance on a final exam is compared to assess the impact of homework on student performance.
You investigate the relationship between air pollution in different major cities over the years by analyzing existing records.
You are curious about how light and water can impact plant growth, so you investigate the effects of different combinations of light and watering amounts on plant growth. You control for various factors such as weather, temperature and soil conditions.
The behaviour of children at recess are studied, and factors such as how they play and socialize are recorded.
2.4 Estimation
A particular inferential problem where we try to estimate a quantitative property of the population
This quantitative property is called a population parameter
Question: What proportion (a quantitative population parameter!) of UBC undergrads have an iphone?
Estimation
Step 1: randomly select a subset (a sample) and ask them if they have an iPhone
Step 2: calculate the proportion in our sample (a statistic or point estimate) and use it as an estimate of the true population proportion.
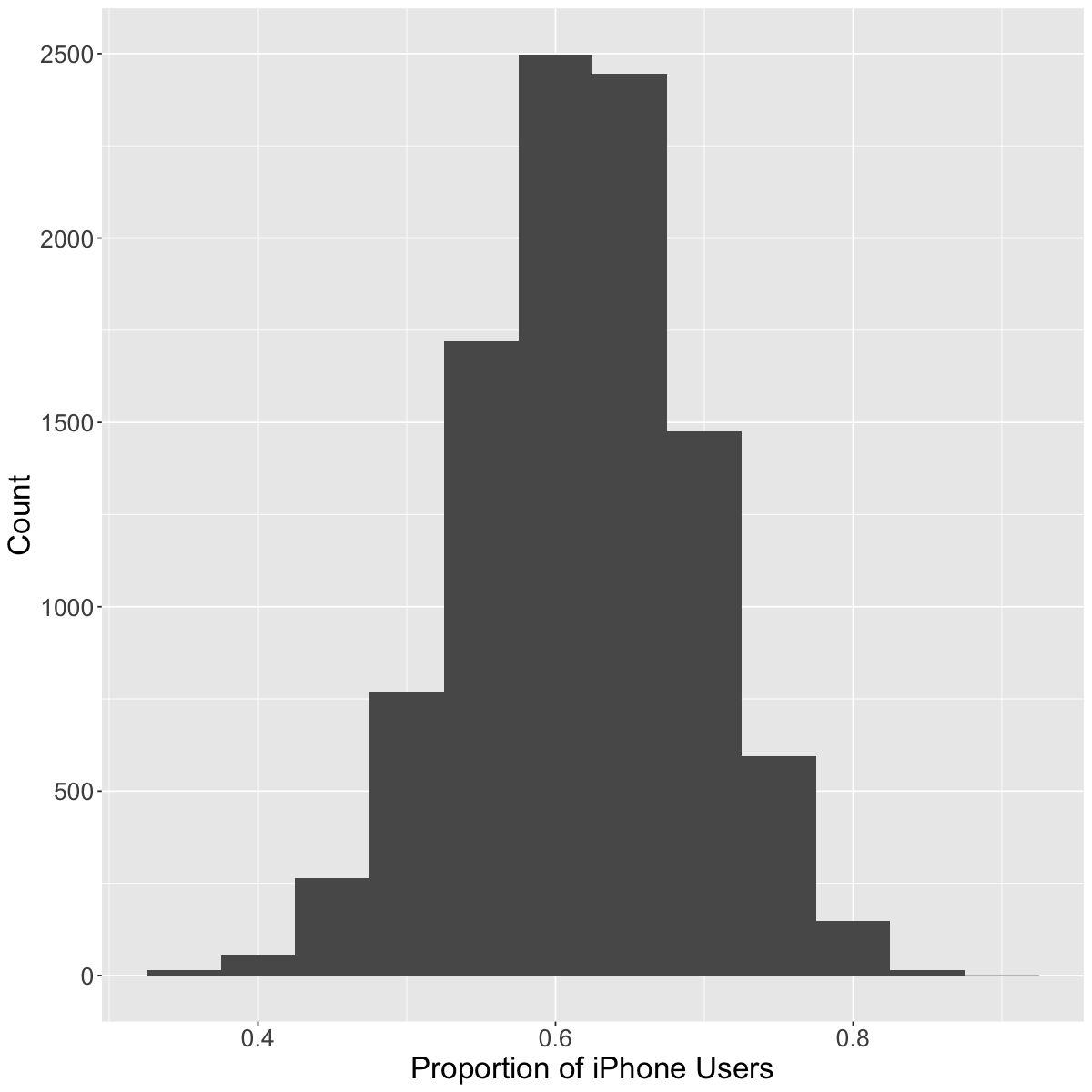
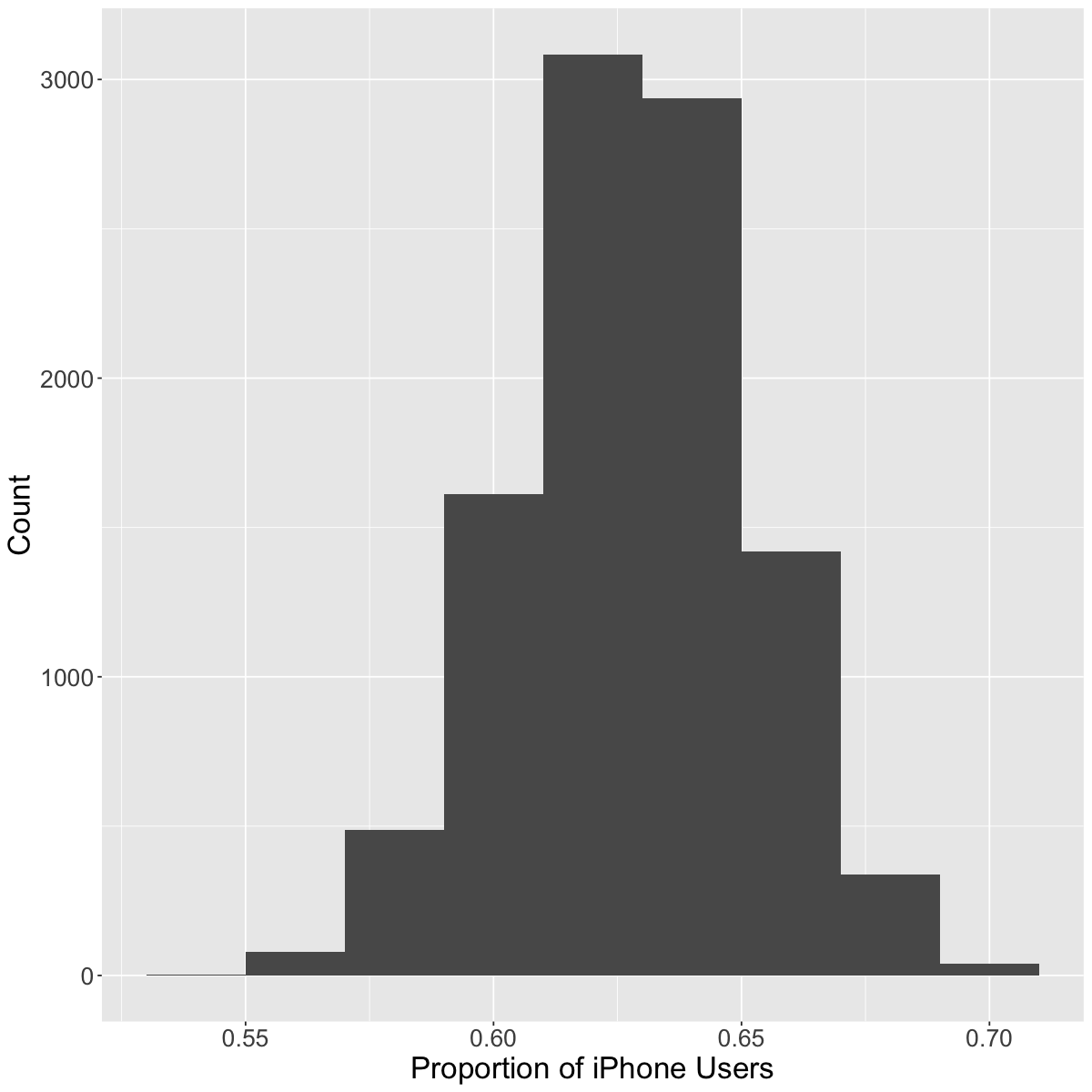
The variability from sample to sample is described as sampling variability.
Virtual simulation experiment
Now, let’s simulate this process to see how well sample estimates reflect the true population parameter!
Question: What proportion of UBC undergrads have an iPhone?
Let’s create a virtual group of students (our population) where 63% of the students have iPhones
Then:
collect a random sample of 40 students,
calculate a proportion of students with iPhones
Our virtual UBC students (population)
Let’s examine our population of 50,000 students. Remember that the true proportion of iPhone users is 63%.
# load libraries for wrangling and plottinglibrary(dplyr)library(infer)
Ok, so we noticed that there is variability from sample to sample. But what if we were to increase the sample size from \(40\) to \(400\)? What do we think will happen?
As we have more observations, the sampling variability decreases
With fewer observations, the sampling variability increases
3. Bootstrapping
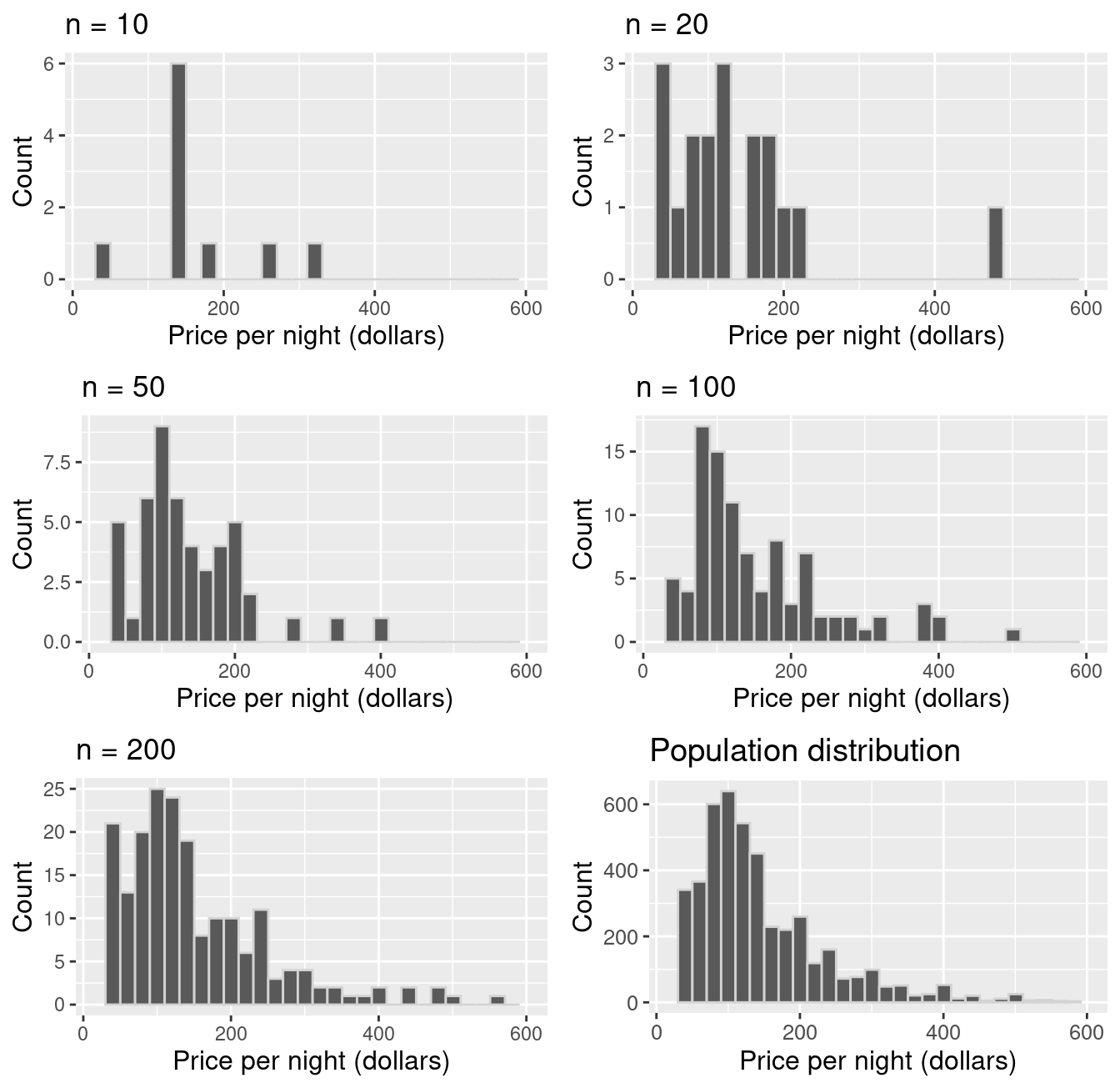
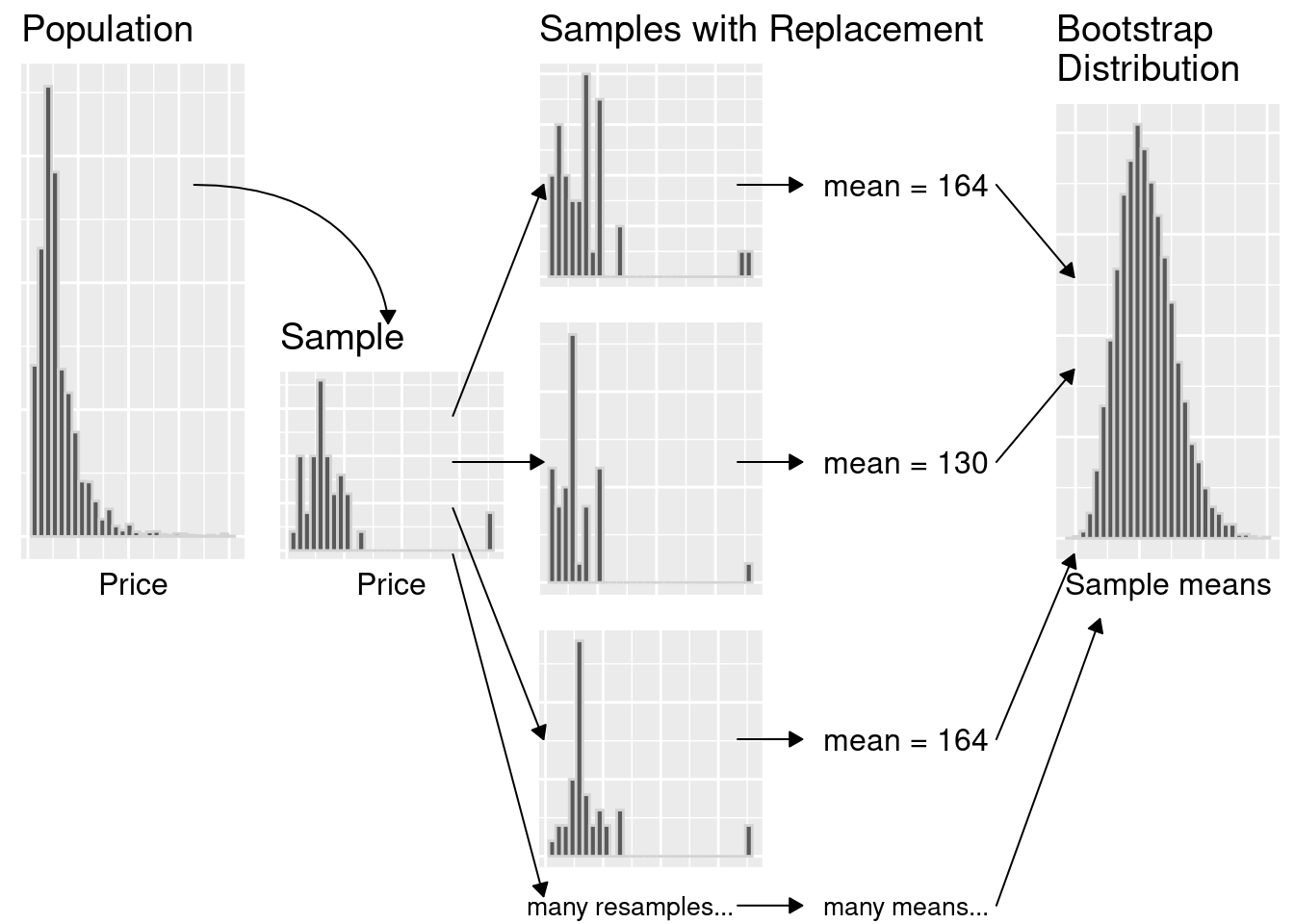
We only have one sample… but if it’s big enough, the sample looks like the population!
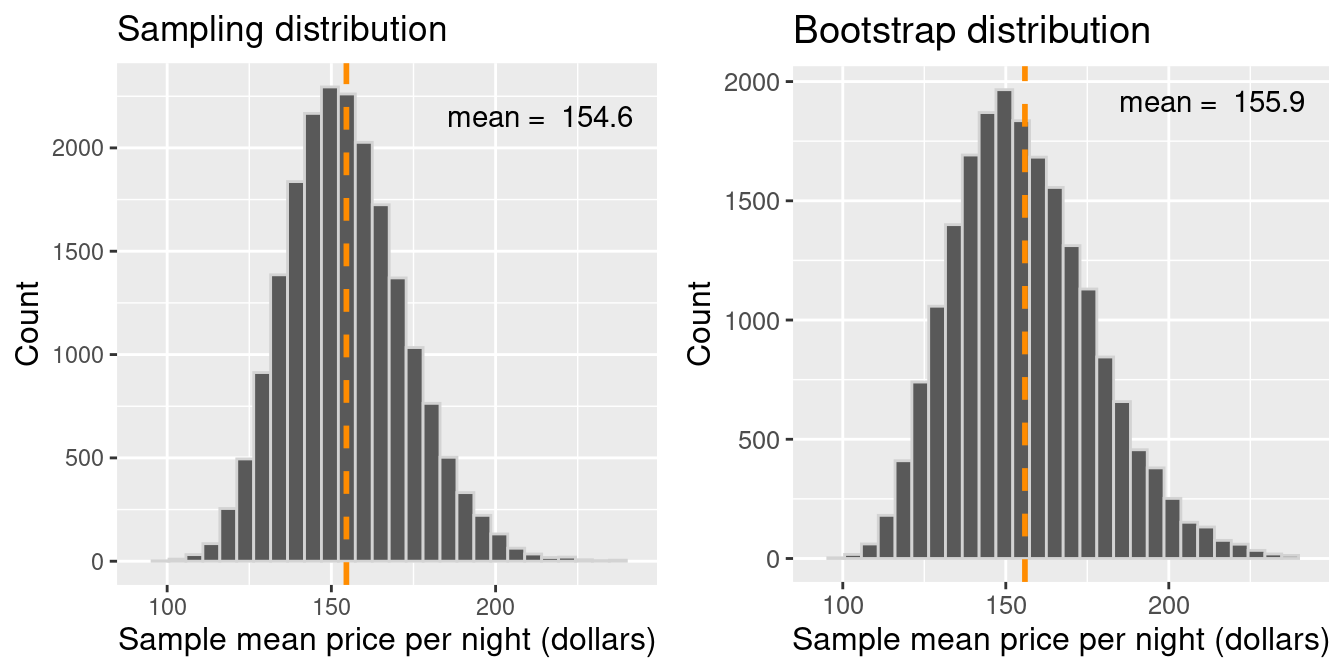
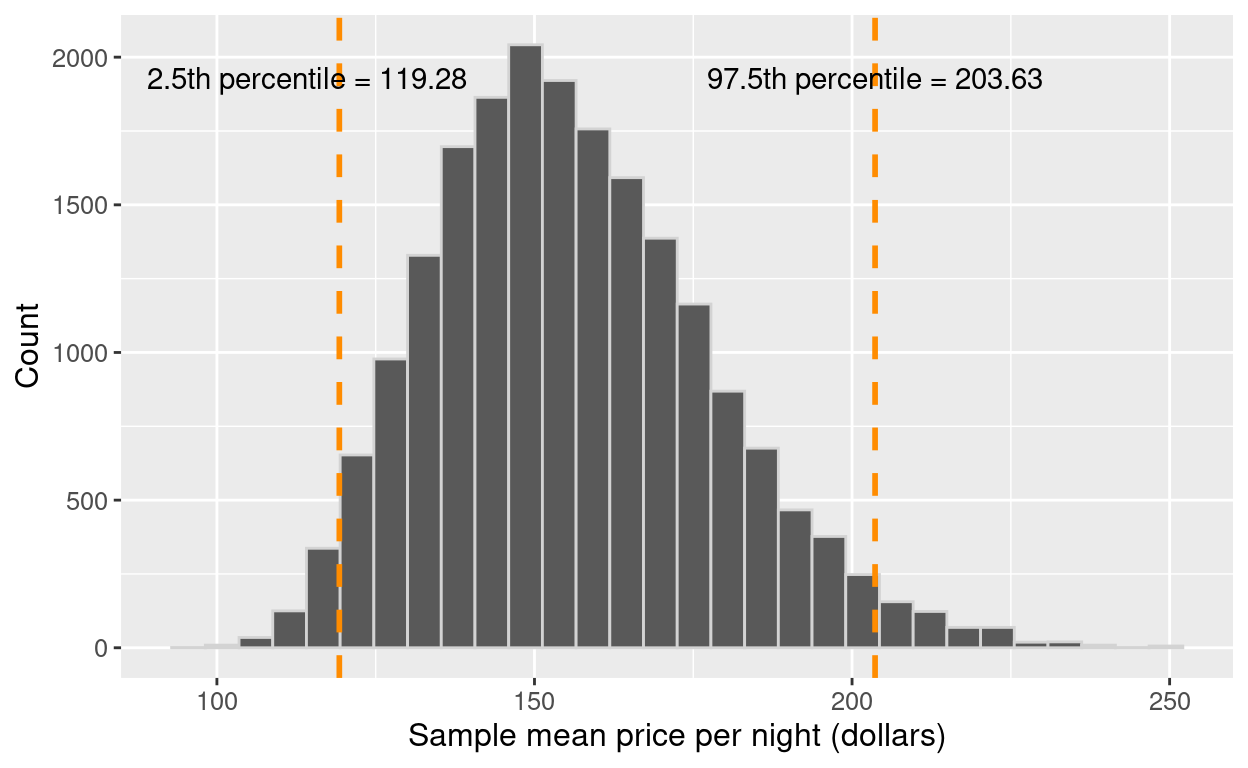
Let’s pretend our sampleis our population. Then we can take many samples from our original sample (called bootstrap samples) to give us an approximation of the sampling distribution (the bootstrap sampling distribution).
Note that by taking many samples from our single, observed sample, we do not obtain the true sampling distribution, but rather an approximation that we call the bootstrap distribution.
Generating a single bootstrap sample
Randomly draw an observation from the original sample (which was drawn from the population)
Record the observation’s value
Return the observation to the original sample
Repeat the above the same number of times as there are observations in the original sample